Kafka Basics
I’ve been learning Apache Kafka over the past week. I took the Udemy course Apache Kafka Series - Learn Apache Kafka for Beginners v3. This blog covers the theory part of Kafka.
Topics, Partitions and Offsets
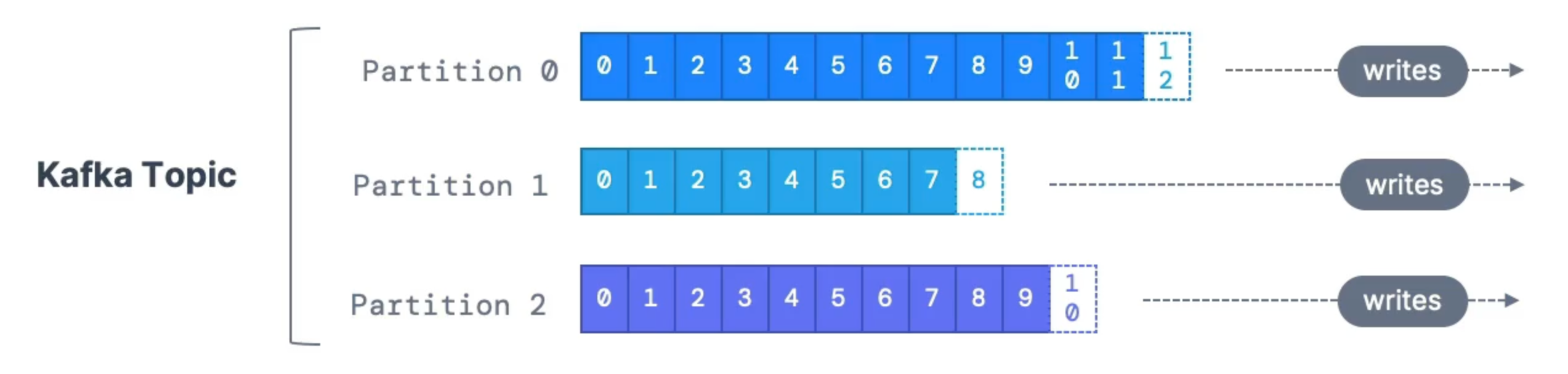
Here are some important notes:
- Kafka is append-only
- Data retention policy (one week by default)
- Order is guaranteed only within a partition
Producers

- When a key is null, data is sent to partitions in round-robin fashion
- When a key is specified, all messages for that key will always go to the same partition (using hashing). This is useful when you need message ordering.
Messages
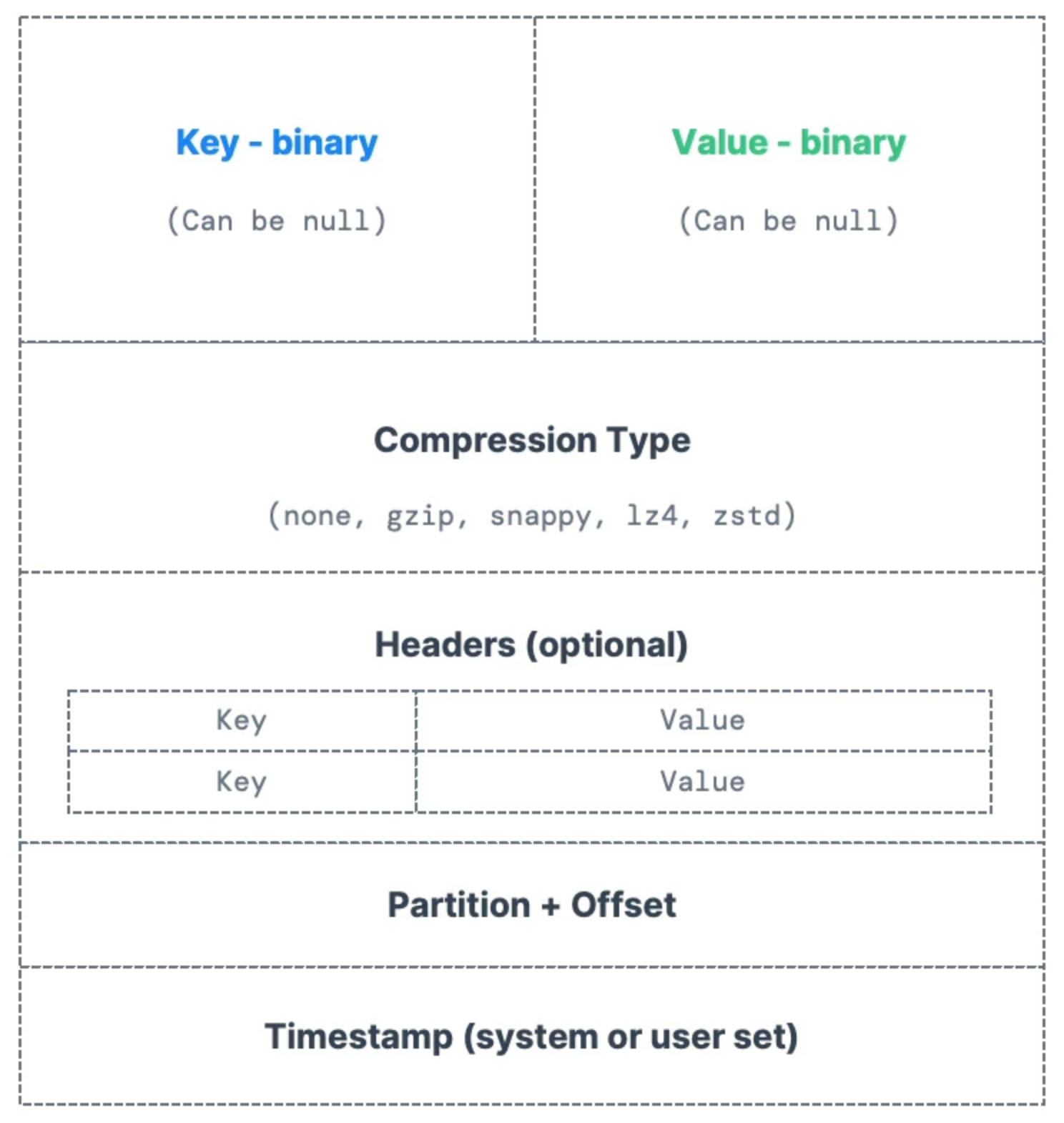
This is what a message payload looks like. Note that the payload is in binary format, so there needs to be serialization and deserialization for messages:
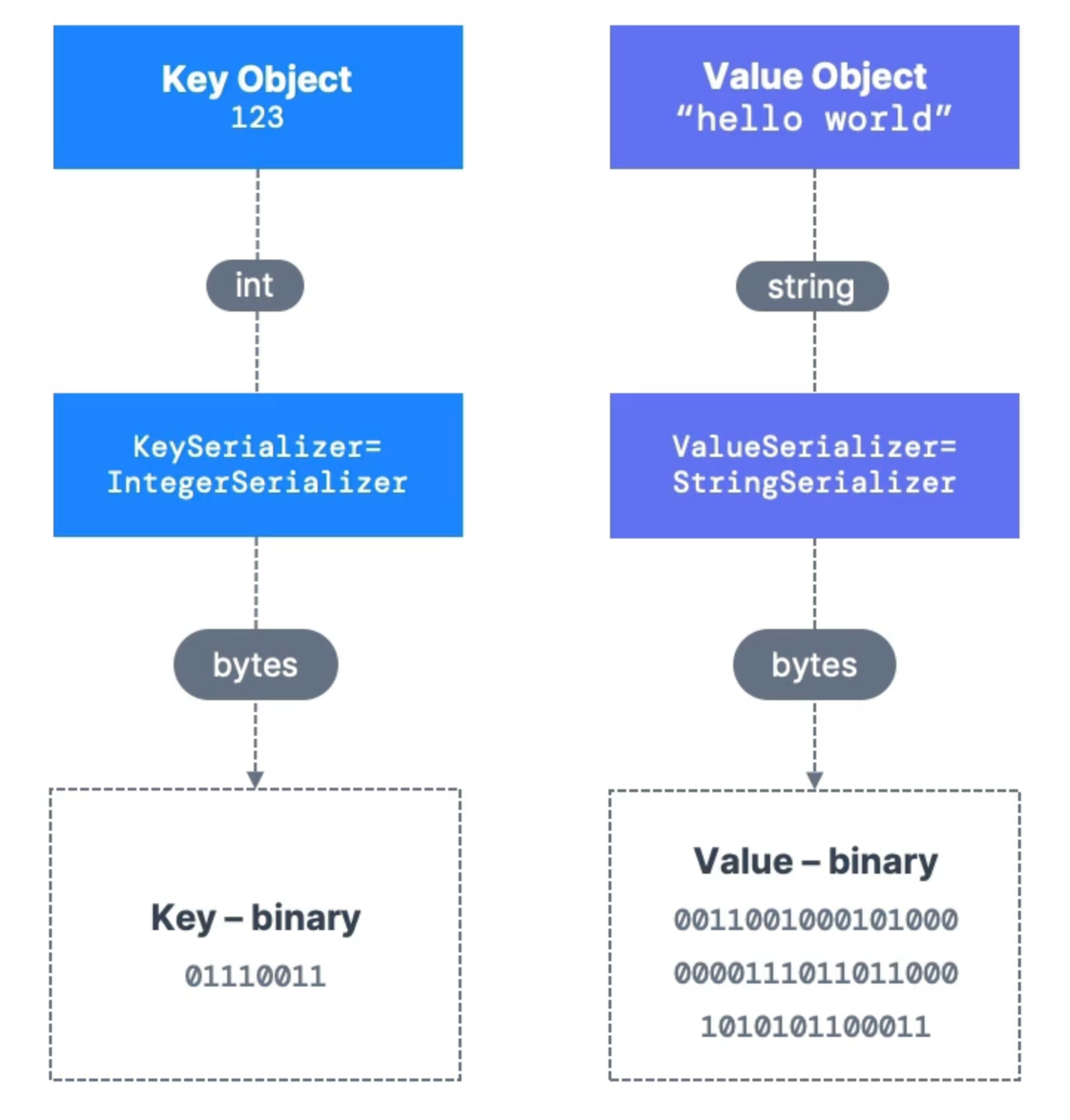
Consumers
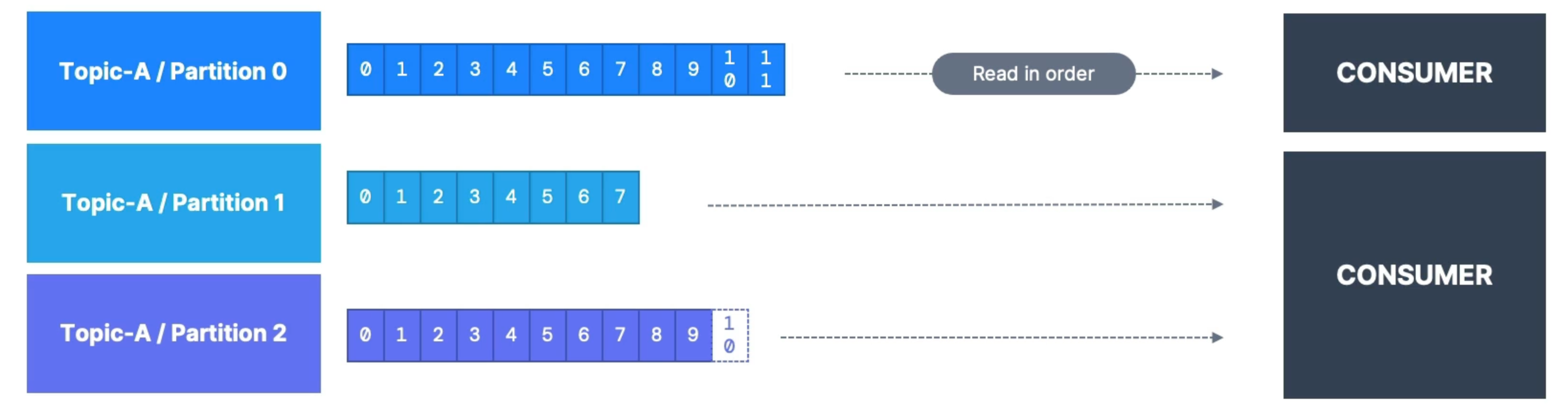
Consumers pull messages from partitions. Data is read sequentially from low to high offset within each partition.
After reading messages, consumers need to deserialize the binary data stored in the messages.
Consumer Groups
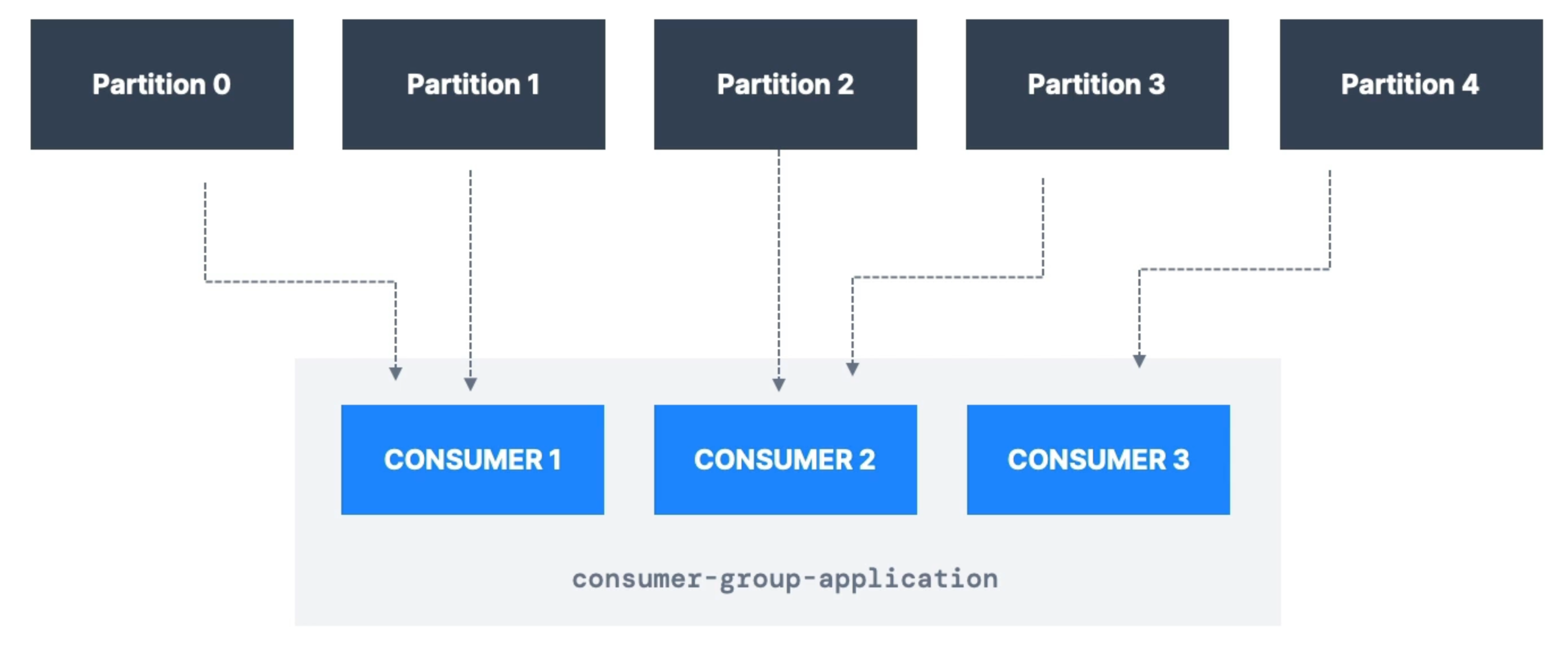
Each consumer within a group reads from exclusive partitions!
This means if you have more consumers than partitions, some consumers will be inactive!
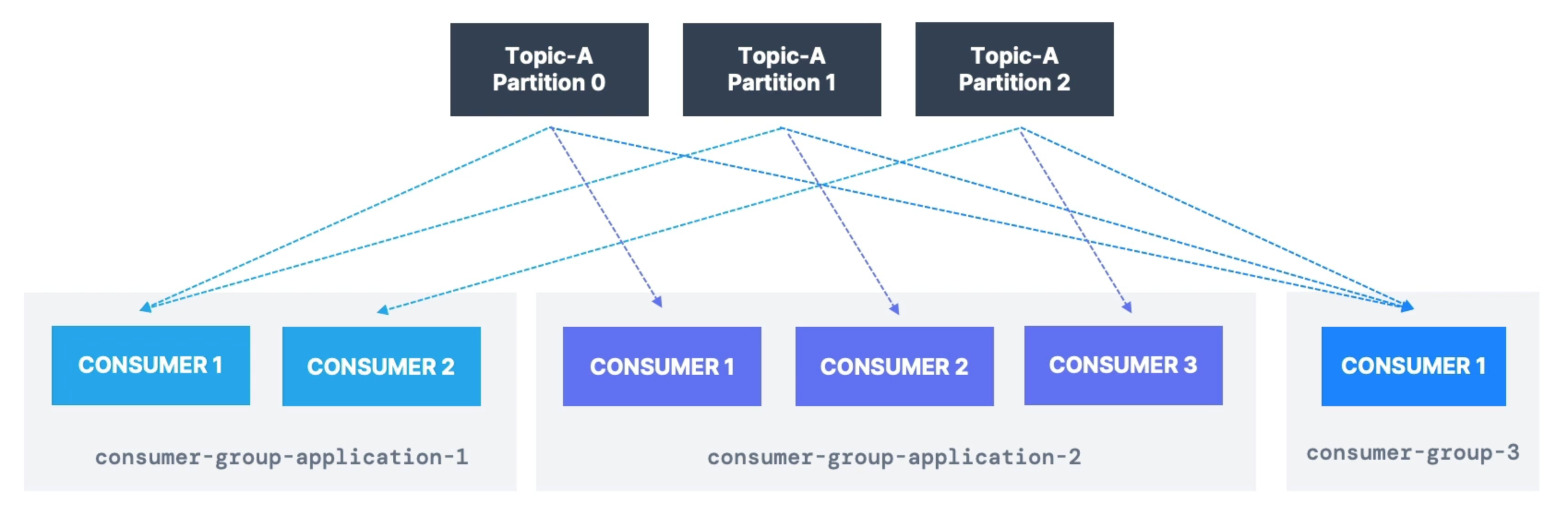
You can also have multiple consumer groups on the same topic!
Consumer Offsets
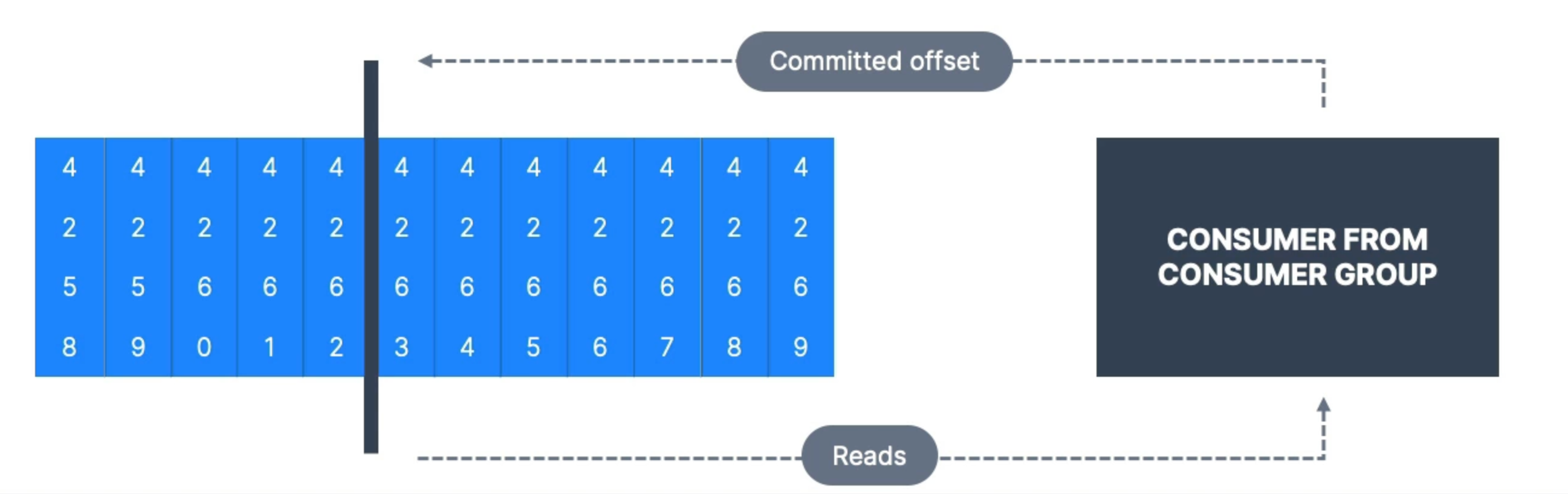
Important concepts:
- Kafka stores the offsets for each consumer group
- Committed offsets are stored in a special
topiccalled__consumer_offsets - When a message is received from Kafka, the consumer periodically commits offsets
- If a consumer dies and recovers, it knows where it left off
Delivery Semantics
- At least once
- Offsets are committed after the message is successfully processed
- Make sure the processing logic is idempotent
- At most once
- Offsets are committed as soon as messages are received
- Exactly once
- Use Kafka transactional API
Broker Discovery
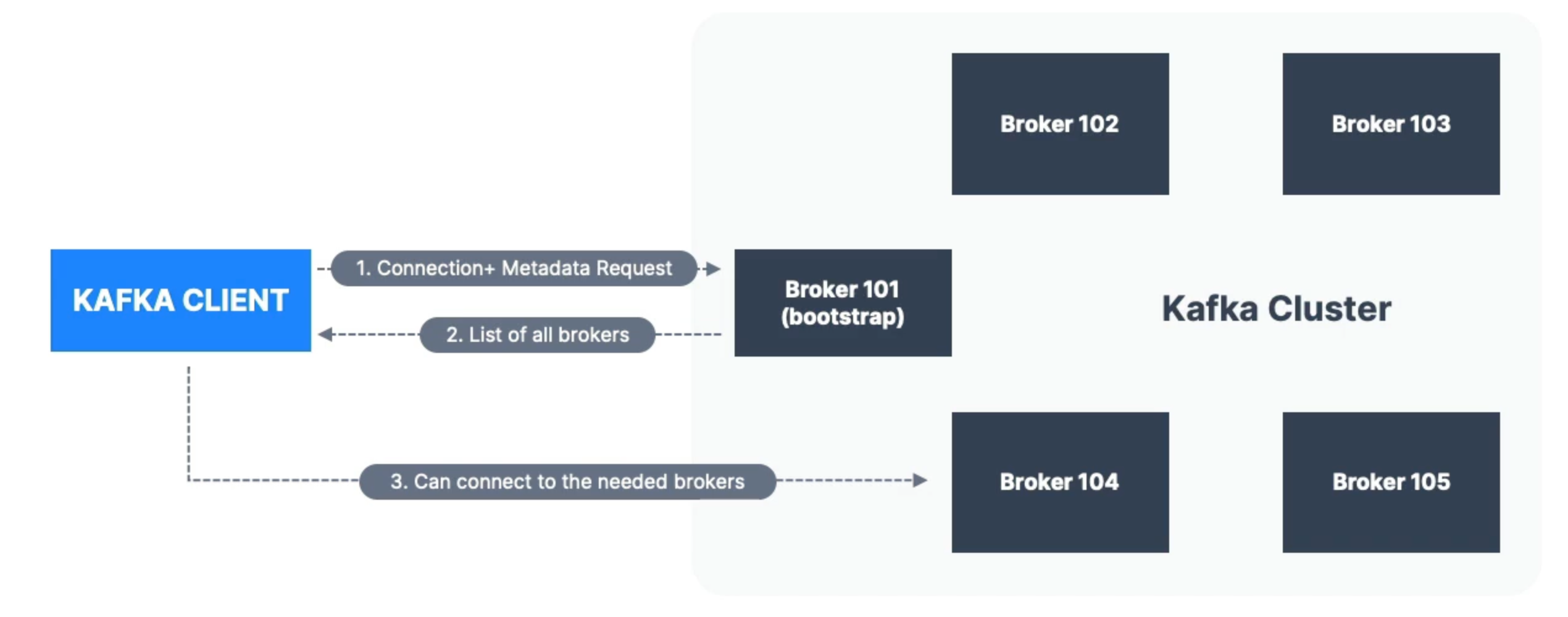
In a Kafka cluster, each broker knows about all other brokers, topics, and partitions! This is called metadata.
- A Kafka client can connect to any broker in the cluster
- The broker will then send the complete list of brokers in the cluster along with other metadata information
- The client can then connect to other brokers
Topic Replication Factor
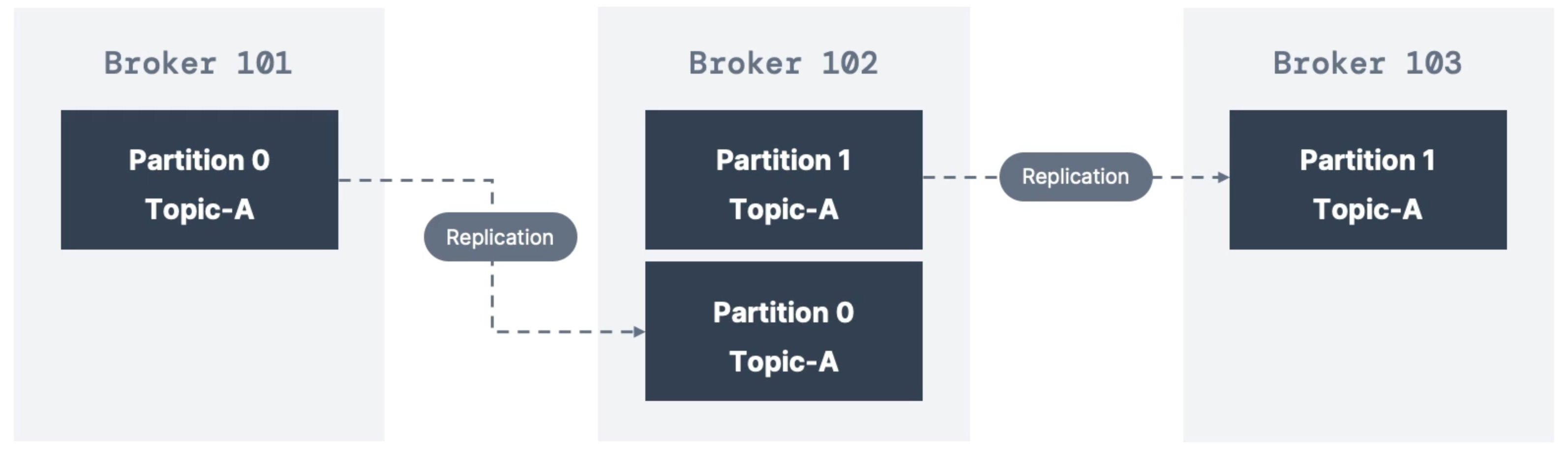
Above is an example of Topic-A with 2 partitions and a replication factor of 2.
With this setup, if a broker goes down, another broker can still serve the data.
Leader
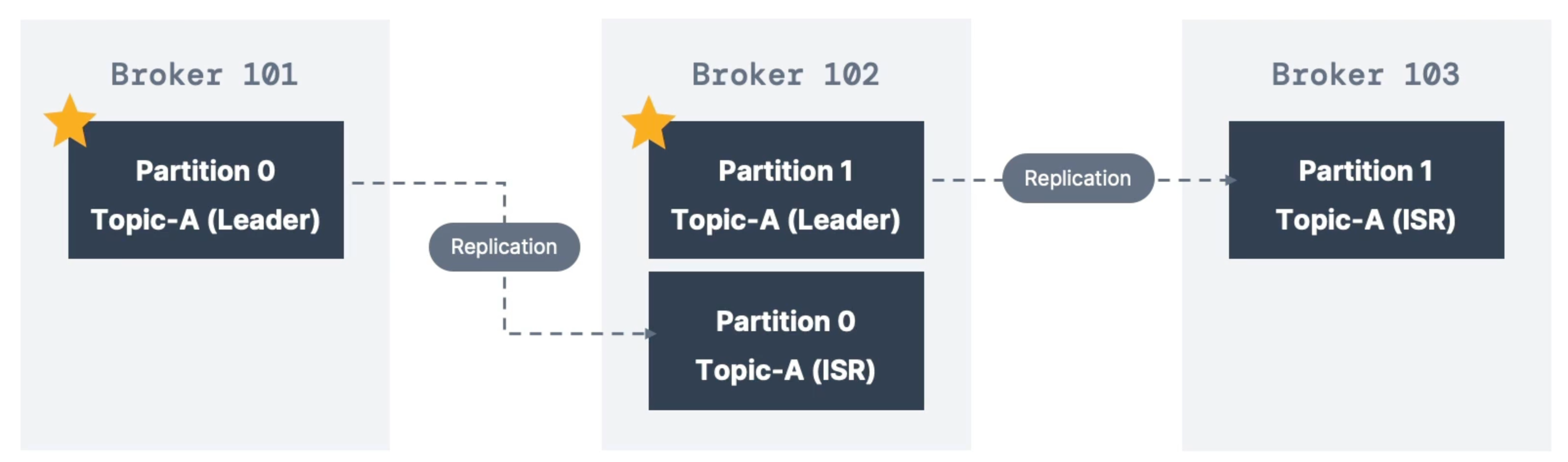
Important concepts:
- Leader: Only one broker can be the leader for a given partition
- Producers can only send data to the broker that is the leader of a partition
- Other brokers will replicate the data
- If a partition is in sync with the leader’s partition, we call it ISR (In-Sync Replica)
Originally, both producers and consumers only used the leader partition. Later (Kafka v2.4+), consumers can be configured to read from the closest replica.
Acknowledgements
Producers can choose to receive acknowledgement of data writes:
acks=0: Won’t wait for acknowledgment (possible data loss)acks=1: Wait for leader acknowledgment (limited data loss)acks=all: Wait for leader + replica acknowledgments (no data loss)
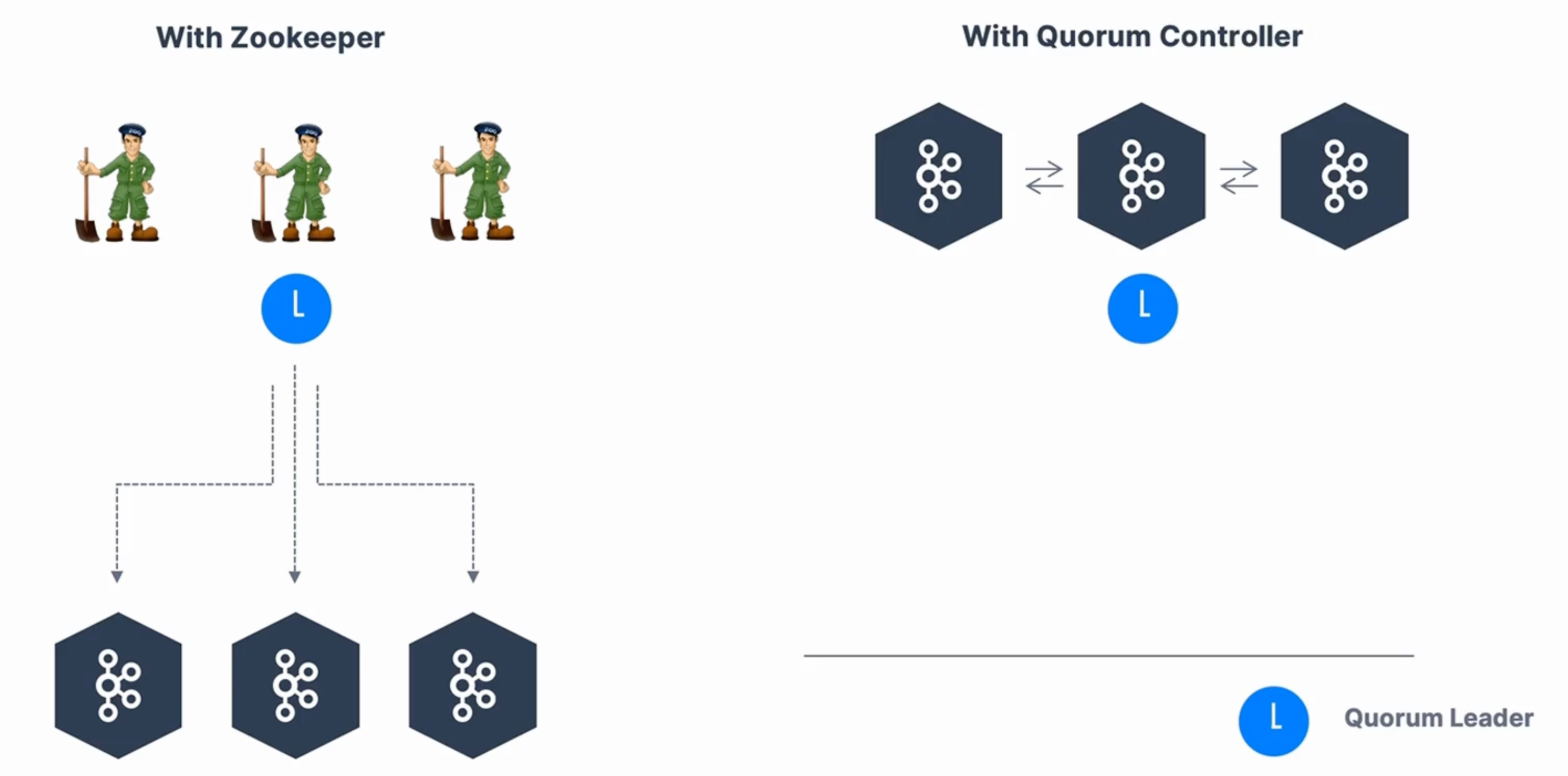
Zookeeper

In short, ZooKeeper will eventually be deprecated. The Kafka community is working hard to remove it (KIP-500, announced in 2020). Therefore, for CLI clients and programs, do not connect to ZooKeeper. The Kafka broker has the discovery mechanism. If you are managing Kafka clusters, you may still need to use it until version 4.0.